Gemini 2.5 Flash: What's new about this Cost-Effective Reasoning Model

Ever since Google launched Gemini 2.5 Pro, I’ve been closely following their latest moves in the AI space. Now, with the arrival of Gemini 2.5 Flash—a new AI reasoning model focused on delivering exceptional value—Google has given developers like me something to get truly excited about. If you care about cost, speed, and large-scale reasoning (like I do), Gemini 2.5 Flash is a game-changer.
Gemini 2.5 Flash: New Features and Hands-On Experience
Unlike the Pro series, which is all about maximum performance and deep reasoning, Gemini 2.5 Flash strikes a smart balance between speed, cost, and performance. Personally, I find this approach perfectly aligned with current AI trends: we need models that are fast and affordable, but still deliver solid results. What really impressed me is that Gemini 2.5 Flash supports a wide range of input formats—including text, images, audio, and video—and boasts a massive 1 million token context window. That’s a solid foundation for any use case requiring large-scale, low-latency inference.
1. Innovative Hybrid Reasoning Architecture
When it comes to the gemini 2.5 flash thinking mode, Gemini 2.5 Flash introduces a unique “Thinking Budgets” mechanism. As a developer, I can set a reasoning budget (from 0 to 24,576 tokens), giving me fine-grained control over how deeply the model thinks:
- With a budget set to 0, the model delivers high-quality results at ultra-low cost and latency—sometimes even outperforming Gemini 2.0 Flash.
- If I enable deeper reasoning, the model automatically allocates more resources based on task complexity, boosting output quality as needed.
This flexible mechanism enables me to freely balance quality, cost, and speed, making it especially suitable for large-scale deployments or cost-sensitive applications. In addition, Gemini 2.5 Flash can display its reasoning process. I really like this feature because I can see how it debates with itself and ultimately makes decisions, which helps me judge whether it has correctly understood my intentions.
⚡ The latest Gemini 2.5 Flash has arrived on the leaderboard! Ranked jointly at #2 and matching top models such as GPT 4.5 Preview & Grok-3! Highlights:
— lmarena.ai (formerly lmsys.org) (@lmarena_ai) April 17, 2025
🏆 tied #1 in Hard Prompts, Coding, and Longer Query
💠 Top 4 across all categories
💵 5-10x cheaper than Gemini-2.5-Pro… pic.twitter.com/qdY2t4cC43
2. Multimodal Power and Massive Context
The multimodal capabilities of Gemini 2.5 Flash are equally impressive. It doesn’t just handle text—it can process images, audio, and even video, making it perfect for complex data and cross-domain applications. And with a context window of up to 1 million tokens, it far surpasses most mainstream models. That means I can use it for ultra-long documents, multi-turn conversations, or summarizing vast datasets—hugely expanding what’s possible in practice.
Benchmark Performance
In real-world tests, Gemini 2.5 Flash delivers outstanding results. On the LMArena Hard Prompts benchmark, its performance is second only to Gemini 2.5 Pro—putting it right at the top of the industry. On the widely watched Humanity’s Last Exam (HLE) benchmark, Gemini 2.5 Flash scored 12%, beating out Claude 3.7 Sonnet and DeepSeek R1, and coming close to OpenAI o4-mini (14%). These numbers give me a lot of confidence in its practical capabilities.
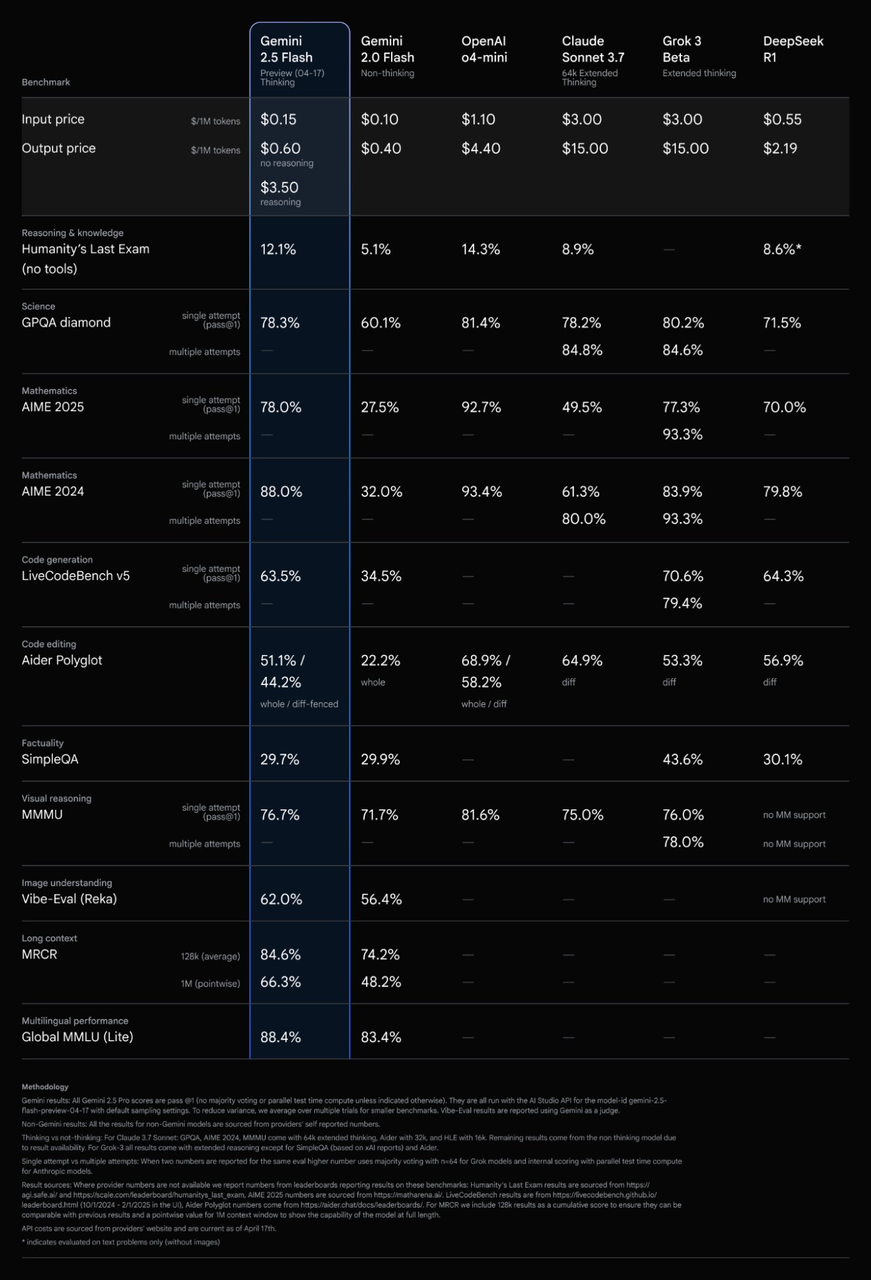
API Pricing: The Best Value in Top-Tier AI
From a pricing perspective, Gemini 2.5 Flash truly earns its reputation as one of the most affordable models among top-tier AI offerings. The flexible pay-as-you-go billing system, combined with the innovative reasoning budget feature, lets developers pick the best option for their needs:
- Input pricing:
Text/Image/Video: $0.15 per million tokens
Audio: $1.00 per million tokens
- Output pricing:
No reasoning (budget = 0): $0.60 per million tokens (incredibly fast and cheap)
With reasoning: $3.50 per million tokens (higher quality, higher cost)
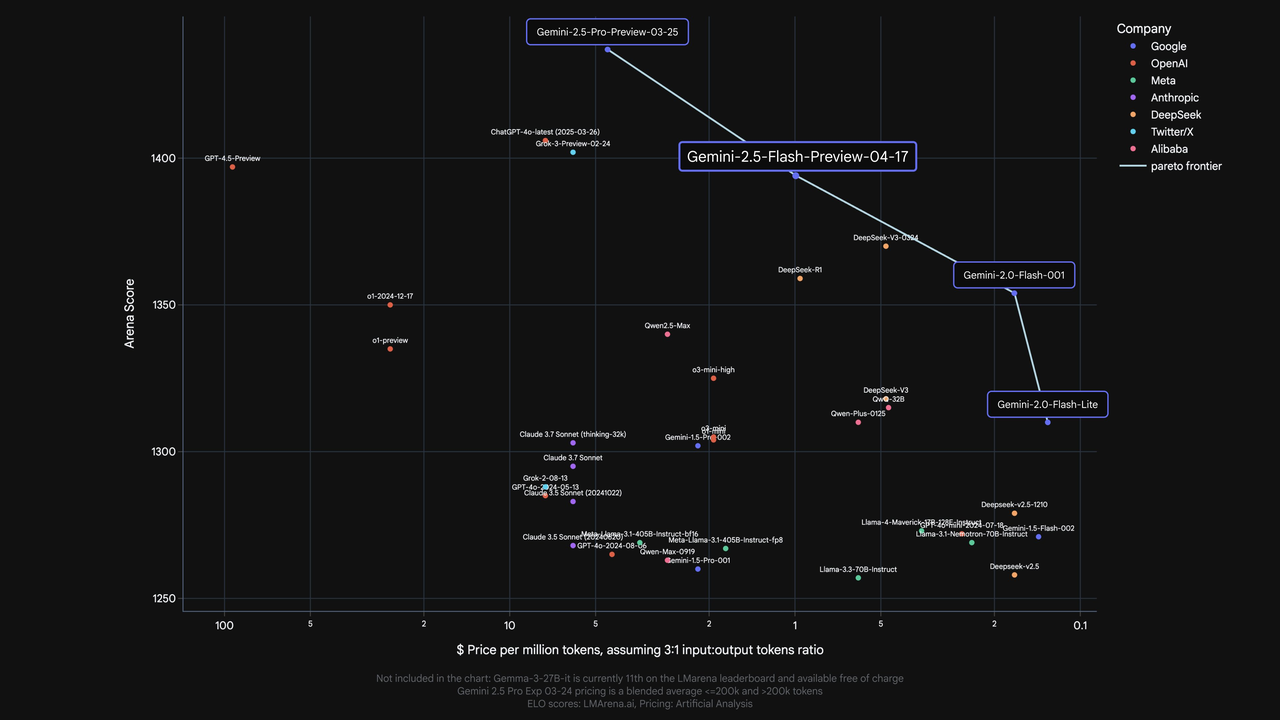
Compared with other leading models from Google, OpenAI, Meta, Anthropic, DeepSeek, Alibaba, and more, Gemini 2.5 Flash stands out as one of the cheapest options per million tokens—far less expensive than GPT-4.5 or Claude 3.7 Sonnet. In terms of performance, its LMArena score is just a notch below flagship models like Gemini 2.5 Pro and GPT-4.5, but well ahead of other models in its price range. The value for money is simply outstanding.
How to Try and Integrate Gemini 2.5 Flash
Right now, Gemini 2.5 Flash is already available in Google AI Studio, Vertex AI, and the Gemini App. As a developer, I can easily access it via the gemini 2.5 flash api, which is super convenient. The Monica platform will also soon integrate gemini 2.5 flash, giving Monica subscribers early access to this high-value AI model.
Looking ahead, Google plans to bring Gemini 2.5 Flash to on-premises environments via Google Distributed Cloud (GDC) in Q3 2025. This will help organizations meet strict data governance requirements and support deployment on Nvidia Blackwell systems, opening up even more enterprise use cases for gemini 2.5 flash experimental.
If you’re interested in more technical details, the gemini 2.5 flash reddit community on Reddit is full of developers sharing hands-on experiences and best practices—definitely worth checking out.