Llama 4 Reality Check: How Meta’s Multimodal Ambitions Are Playing Out
Explore how Meta’s Llama 4 models perform in practice versus their claims.

In the fast-moving world of AI, Meta’s Llama 4 was supposed to be a major release—positioned as the company’s answer to OpenAI’s GPT-4o and Google’s Gemini 1.5. But while the announcement generated a lot of buzz, the actual product has landed with mixed, and often disappointed, reactions.
This article takes a step back from the promotional slides to look at what Llama 4 actually offers, how it performs in everyday scenarios, and why it might not live up to the expectations Meta set for it.
l.Llama 4: Meta's multimodal model, why has its reputation declined so quickly?
What Meta Promised (and What’s Really There)
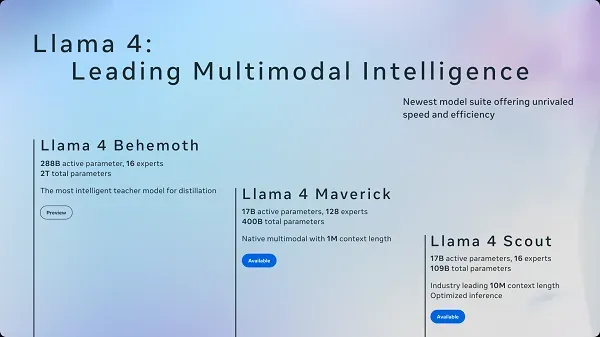
Meta introduced three core models in the Llama 4 series, each aimed at a different kind of use case:
Scout: A compact, efficiency-focused model that can run on a single NVIDIA H100 GPU. It’s meant to handle long-form documents with an extremely large “context window” (reportedly up to 10 million tokens). That sounds impressive—but in practice, real users often find it struggles with far less.
Maverick: A mid-sized model designed for coding, logical reasoning, and chat. Meta says it performs well in popular open benchmarks like LMSYS Arena, with a decent ELO rating of 1417. But user feedback suggests it’s competent, not groundbreaking—especially compared to newer versions of GPT-4o.
Behemoth (not yet released): The heavyweight of the group, reportedly featuring over 2 trillion parameters. Meta claims it beats GPT-4.5 and Claude Sonnet in STEM tasks—but without public access or reproducible results, it’s difficult to evaluate.
Behind the scenes, all three models rely on Mixture-of-Experts (MoE) architecture—a method where only parts of the model activate at a time to save compute. That’s a smart engineering choice, but for most users, what matters isn’t how it works—it’s whether it works.
For Non-Developers: What Should You Take Away?
Llama 4 can process both text and images, but image comprehension still trails far behind GPT-4o. Some users even posted examples of completely incorrect outputs.
The 10M token memory sounds futuristic, but in practical usage, the model starts breaking down well before that mark.
- You can download and modify the model, which is great for researchers. But it’s not fully open-source in the way many assume—Meta retains license control.
II. Technical Highlights: What Actually Matters to Users?
Meta built Llama 4 with several engineering upgrades aimed at making the model faster, smarter, and more flexible. But are they features users actually benefit from?
One major change is its use of a Mixture of Experts (MoE) system. Instead of using the entire neural network to answer every question, the model activates only a small group of “experts” at a time. In theory, this makes Llama 4 faster and more efficient—kind of like assigning tasks to specialists rather than involving everyone.
For example, Maverick, the mid-sized version of Llama 4, uses 128 expert modules plus a shared layer to handle tasks more efficiently. While this design helps with scalability, its real-world advantages are less obvious unless you’re deploying it in production environments.
Native Multimodality—With Limits
Another key promise: Llama 4 is designed to work not just with text, but also with images, and (eventually) audio and video. Meta calls this a “native multimodal” design.
Text: Multilingual, long-form dialogue works reasonably well
Images: Basic tasks like image captioning or OCR are supported—but far behind GPT-4o in reliability
Audio/Video: Still experimental or unreleased
In practice, even basic image-related tasks have led to disappointing results. Simon Willison, an independent AI researcher, asked Llama 4 Scout to summarize a long Reddit thread (~20,000 tokens). The output was, in his words, “complete junk,” with the model looping and hallucinating instead of summarizing.
Context Window: Big Numbers, Small Gains?
Meta claims Scout can handle up to 10 million tokens of input. That’s a huge number—meant to suggest the model can remember entire books, transcripts, or codebases. But users have reported that performance begins to degrade well below that, often around just 10,000–20,000 tokens.
So while the theoretical ceiling is high, the practical benefits for most users are limited.
III. Performance in the Wild: Not Quite a GPT-Killer
Meta says Llama 4 holds its own—or even outperforms—closed-source models like GPT-4o and Gemini 2.0 in specific tasks. Internally, the Scout model was benchmarked to outperform Gemini 2.0 Flash-Lite and Mistral 3.1 on resource-limited hardware. For lightweight environments, that may be true.
Maverick, the more powerful variant, reportedly does well in code generation and logic tasks, scoring a 1417 ELO on LMSYS Arena. That’s solid, but not elite.
However, these claims come with a catch: the version of Maverick Meta submitted to LMArena isn’t the same as the one publicly released. AI researcher Daniel Lemire and others have flagged this as misleading, arguing it undermines the credibility of the model’s public evaluation.
“The top-ranked Llama 4 model on LMSYS Arena is different from the one Meta released.”
— Daniel Lemire, Professor and AI Benchmark Researcher
Meta hasn’t fully responded to these concerns, and the community is now pressing for more transparency in how open-source models are benchmarked.
IV. Industry Reactions: Real Voices from the Field
The release of Llama 4 triggered immediate reactions across the AI ecosystem—from developers, researchers, and open-source contributors. While Meta executives expressed optimism, many in the broader community took a more skeptical view.
Verified Expert Commentary
Performance and Multimodal Support: Meta officially released two models—Scout and Maverick—based on Mixture-of-Experts (MoE) architecture, supporting multimodal inputs (text and images, with video/audio to come). According to LMSYS Arena, Llama 4 Maverick achieved a 1417 ELO rating, surpassing GPT-4o and Gemini 2.0 Flash in comparative benchmarks. However, some researchers flagged concerns that Meta’s top-performing variant, “Maverick-03-26-Experimental,” was not identical to the open-source release, prompting questions about benchmark transparency. Meta responded that using custom-tuned variants in benchmarks is standard practice across the industry.
Handling Sensitive Topics: As reported by Business Insider, Llama 4 was found to be significantly more responsive on politically or socially sensitive prompts compared to Llama 3.3. Its refusal rate dropped from 7% to under 2%, signaling Meta’s intent to balance safety with expressiveness. Meta claims these changes are part of a broader alignment strategy to reduce bias and promote model transparency.
Infrastructure and Investment: In Meta’s Q1 2025 earnings call, Mark Zuckerberg confirmed that training Llama 4 required “nearly 10x the compute of Llama 3,” involving over 100,000 Nvidia H100 GPUs—the largest known training cluster to date. Meta has also pledged $40 billion in infrastructure investments for 2025 to expand its AI capabilities.
Community Feedback from Twitter/X
Zvi Mowshowitz (@TheZvi): Expressed skepticism about Llama 4's capabilities, stating, "Llama Does Not Look Good 4 Anything.
— Zvi Mowshowitz (@TheZvi) April 9, 2025
Artificial Analysis (@ArtificialAnlys): Llama 4 independent evals: Maverick (402B total, 17B active) beats Claude 3.7 Sonnet, trails DeepSeek V3 but more efficient.
Llama 4 independent evals: Maverick (402B total, 17B active) beats Claude 3.7 Sonnet, trails DeepSeek V3 but more efficient; Scout (109B total, 17B active) in-line with GPT-4o mini, ahead of Mistral Small 3.1
— Artificial Analysis (@ArtificialAnlys) April 6, 2025
We have independently benchmarked Scout and Maverick as scoring 36 and… pic.twitter.com/wwvXaTozeT
lmarena.ai (@lmarena_ai): Meta's interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that 'Llama-4-Maverick-03-26-Experimental' was a customized model to optimize for human preference.
We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. This includes user prompts, model responses, and user preferences. (link in next tweet)
— lmarena.ai (formerly lmsys.org) (@lmarena_ai) April 8, 2025
Early…
Reddit user (@LocalLLaMA): I'm incredibly disappointed with Llama-4. My conclusion is that they completely surpassed my expectations... in a negative direction. The model doesn't look great. All the coverage I've seen has been negative.
I'm incredibly disappointed with Llama-4
by u/Dr_Karminski in LocalLLaMA
Summary Table: What Are Experts Really Saying?
| Source | Key Takeaway |
|---|---|
| LMSYS Arena / The Decoder | Benchmarked Llama 4 Maverick highly, but version discrepancies noted |
| Business Insider | Llama 4 more open in handling sensitive prompts |
| Meta Investor Relations | Over 100K H100 GPUs used for training; $40B AI infrastructure in 2025 |
These insights paint a more nuanced picture than Meta’s promotional messaging. While the technology is promising, users and experts alike continue to call for more transparency and consistency between public releases and benchmarked models.
V.Applications and Integration: From Labs to Feeds?
Despite its issues, Llama 4 has already been integrated into Meta’s platforms like WhatsApp, Messenger, and Instagram. Users can now interact with Meta AI assistants across these apps, although the extent of Llama 4's backend deployment remains unclear.
For everyday tasks like summarizing articles, translating messages, or answering casual questions, it performs adequately. But power users and developers pushing the model with visual tasks or edge cases continue to report inconsistencies.
Meanwhile, on Hugging Face, Llama models have surpassed 650 million downloads. Numerous community-led fine-tuned variants (e.g. “Llama 4 Code Enhanced” or “Llama-Vision v1”) are emerging, aimed at patching current shortcomings.
Meta is also piloting enterprise AI agents to automate customer service and transaction support. These agents, still in trial phases, hold potential but will require tighter alignment and reliability before wide adoption.
Vl. Future Development: What’s Next for Llama 4?

Looking ahead, Meta plans to expand Llama 4 with new variants tailored for reasoning, speech, and multimodal generation. Mark Zuckerberg has stated that Llama 4 training consumed “10x the compute of Llama 3,” reinforcing Meta’s aggressive AI investment.
Key roadmap areas include:
- Native voice interaction (input/output)
- Generative video (Meta MovieGen)
- Long-context reasoning at 100k+ tokens
- Safer alignment for sensitive topics
- Broader use of proprietary AI chips to reduce dependence on Nvidia
However, regulatory limitations—especially in the EU—have blocked Llama 4 from full global availability. And while Meta promotes openness, the combination of license restrictions, inconsistent benchmarks, and still-maturing features has left some wondering: is this a research release or a production-ready tool?
VIl. Final Thoughts: A Milestone with Caveats
Llama 4 is clearly an important step in the evolution of open-source AI. But it’s not quite the turning point Meta has advertised. While its technical innovations are meaningful, the real value will depend on transparency, refinement, and user trust.
For now, Llama 4 serves as a reminder: in AI, it’s not enough to be open. You also have to deliver.