OpenAI.fm: Ultimate Guide to OpenAI's Latest AI Voice Models
Explore OpenAI.fm, the newest AI voice TTS platform powered by OpenAI's text-to-speech and speech-to-text models. Including GPT-4o-mini-tts, gpt-4o-transcribe,gpt-4o-mini-transcribe.Learn about its API pricing, features, applications, use cases.

On March 20, 2025, OpenAI set the developer community buzzing with a low-key technical livestream. The event unveiled OpenAI.fm, a brand-new voice technology platform, alongside three cutting-edge speech-to-text and text-to-speech models that form the technological backbone of the platform.

OpenAI's audio lineup includes two speech-to-text models and one text-to-speech model: gpt-4o-transcribe (speech-to-text), gpt-4o-mini-transcribe (lightweight speech-to-text), and gpt-4o-mini-tts (text-to-speech). According to OpenAI, these models dramatically cut word recognition error rates and boost language recognition capabilities, especially in tough scenarios involving accents, background noise, and varying speech speeds.
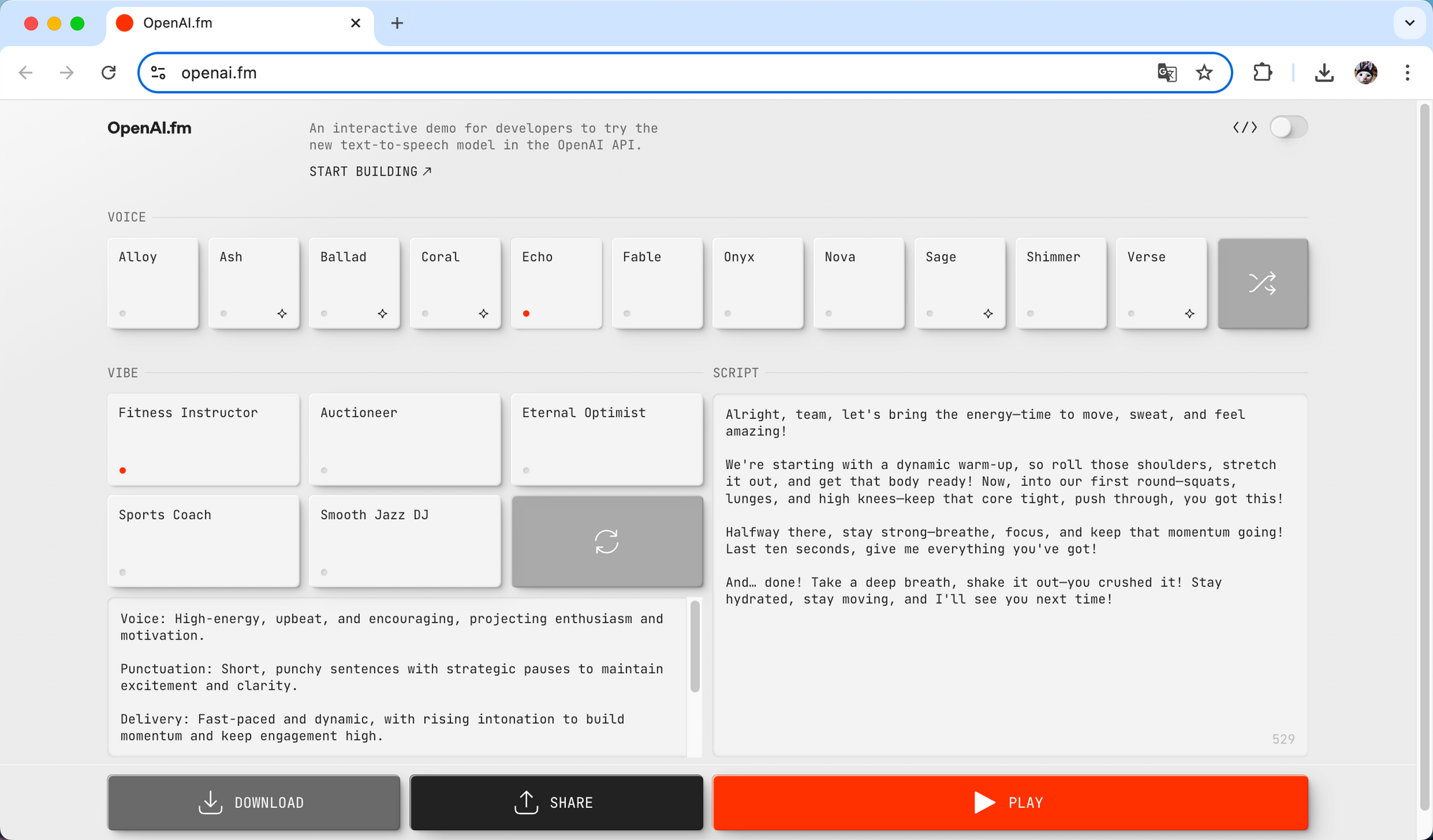
What sets OpenAI.fm apart from traditional voice tech is the sheer quality and flexibility of these models. Users can not only generate natural-sounding speech through simple prompts but also fine-tune the voice's tone, emotion, and style. This "steerability" makes the technology incredibly versatile, finding its place in customer service, content creation, education, and healthcare. The platform also features a developer-friendly Playground tool for quick testing and code generation, making integration into projects a breeze. OpenAI.fm's launch marks a significant leap forward in voice technology, equipping developers with powerful tools for complex voice applications and accelerating the arrival of AI voice agents.
Let's dive into OpenAI.FM's new technology, exploring its features, real-world applications, and how it's reshaping our interactions with AI voice.
OpenAI.fm Platform Core Models
1. OpenAI Speech-to-Text Models (STT)
The gpt-4o-transcribe and gpt-4o-mini-transcribe models leave OpenAI's previous Whisper models in the dust when it comes to accuracy and reliability. These newcomers excel at handling speech recognition in challenging conditions, from diverse accents to noisy environments and varying speech speeds.
gpt-4o-transcribe:
- Dramatically slashes Word Error Rate (WER), outperforming existing Whisper models across multiple benchmarks
- Picks up speech nuances with remarkable precision, cutting misrecognition and boosting transcription reliability
gpt-4o-mini-transcribe:
- The nimble sibling of gpt-4o-transcribe, prioritizing speed and efficiency.
Key Differences:
While cut from the same cloth, gpt-4o-transcribe is the heavyweight champion offering unmatched accuracy and comprehensive features. Meanwhile, gpt-4o-mini-transcribe is its streamlined counterpart, using knowledge distillation to shrink the model size. It uses 60% less memory, responds twice as fast, and costs half as much ($0.003/minute) while maintaining impressive accuracy.
Hearing More Accurately, Making Fewer Mistakes
In the speech recognition world, accuracy is king. A transcript riddled with errors ruins the user experience. That's why transcription accuracy is the gold standard for evaluating ASR (Automatic Speech Recognition) models. To put their new models to the test, OpenAI ran them through the FLEURS multilingual speech benchmark and other rigorous evaluations. The results speak for themselves:
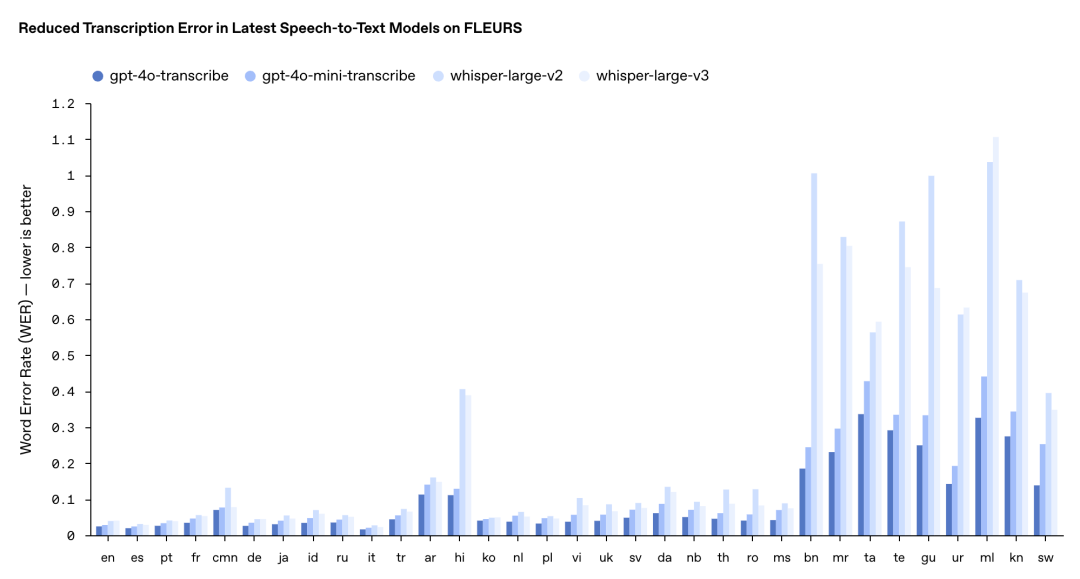
The FLEURS multilingual test shows gpt-4o-transcribe and gpt-4o-mini-transcribe leaving Whisper v2 and v3 in the rearview mirror. For English and Spanish, gpt-4o-transcribe's error rate hovers around a mere 2%. In French and Spanish tests, the new models scored WERs of 5.2% and 6.1% respectively, handily beating Whisper v3's 7.8% and 8.5%.
Even more impressive, in OpenAI's noisy environment demos (like street scenes with SNR<10dB), the new model achieved a WER of just 8.3%—a 33% improvement over Whisper v3's 12.5%. This means substantially more reliable transcriptions in real-world noisy settings. That said, while gpt-4o-mini-transcribe nearly matches the flagship in quiet environments, it does show slightly higher error rates in challenging scenarios with rapid speech or heavy background noise.
Perfect Fit Scenarios
gpt-4o-transcribe: Real-time transcription for international meetings, multilingual customer service centers, and making sense of recordings in noisy environments.
gpt-4o-mini-transcribe: Resource-conscious devices like smartwatches and in-car systems, and local voice command processing.
Leaving Whisper in the Dust
OpenAI's new audio models outshine the older Whisper models in several key ways:
- Sharper accuracy: Significantly fewer errors across multiple languages, accents, and noisy environments.
- Lightning-fast responses: Support for streaming API and real-time meeting scenarios, with text generation within 0.3 seconds of audio input—40% faster than before.
- Feature-rich experience: Support for timestamp annotation, streaming transcription, and real-time API to meet diverse application needs.
- Budget-friendly pricing: Especially gpt-4o-mini-transcribe at just $0.003 per minute—half the cost of Whisper.
These improvements have catapulted OpenAI's new audio models to the forefront of speech recognition and synthesis, giving developers more powerful, flexible tools to build next-generation voice applications.
2. OpenAI Text-to-Speech Model (TTS)
gpt-4o-mini-tts:
- Pioneering "Steerability": Developers can control not just what the model says, but how to says.
- Natural language prompt like "speak like a compassionate customer service rep" or "channel a mad scientist" adjust the AI voice's style, tone, and emotion. This steerability breaks new ground for voice synthesis, freeing AI-generated voices from monotonous, robotic delivery and enabling rich emotional expression and personality.
- The model can even mimic specific accents, like English with an Italian flair, and seamlessly hop between languages while maintaining consistent voice quality. This versatility lets developers pick the perfect voice for any scenario.
- At just $0.015/minute, gpt-4o-mini-tts API pricing undercuts similar products by a wide margin.
- Sound quality is top-notch, with 48kHz sampling rate and neural vocoder technology. Signal-to-noise optimization reaches 18 decibels—approaching professional studio quality. In subjective MOS (Mean Opinion Score) testing, the model scored an impressive 4.2/5, handily beating traditional TTS models like Google WaveNet's 3.8/5
Speaking More Naturally, Sounding More Real
Unlike old-school TTS systems, OpenAI's gpt-4o-mini-tts uses voice print decoupling algorithms that separate voice characteristics from semantic understanding during training. This lets developers fine-tune the voice library independently for precise control over output. Under the hood, conditional generative models work alongside attention mechanisms and style embedding to enable pinpoint control over intonation, rhythm, and emotion—the technical secret sauce behind the model's "steerability."
This isn't just stitching together pre-recorded voice clips; gpt-4o-mini-tts genuinely understands the meaning and emotion behind the text, creating cohesive, natural-sounding output. It doesn't just read words—it comprehends content and transforms it into speech that's nearly indistinguishable from a human voice. It's like having a professional voice actor on standby in your app or content, ready to deliver your text with perfect inflection.
OpenAI's platform guide offers these tips for gpt-4o-mini-tts:
| Instruction Dimensions for Steerability | Accent, Emotional range, Intonation, Impressions, Speed of speech, Tone, Whispering |
| Distinct Voices | Alloy, Ash, Ballad, Coral, Echo, Fable, Onyx, Nova, Sage, Shimmer, Verse |
| Supported Languages | Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, Welsh |
| Pro Tip | After extensive testing, the specially optimized English synthesis sounds the most natural. |
| Customizable "Vibes" | From calm and professional to medieval knight, true crime enthusiast, friendly companion, robot bedtime storyteller, and many more styles |
| Voice Generation Suggestions |
|
Real-World Applications
- Content creators can add professional voiceovers to videos, podcasts, or audiobooks without expensive equipment or voice talent
- Educators can create engaging learning materials that make abstract concepts click through vivid explanations
- Developers can build natural voice interfaces that enhance user experience
- Accessibility features allow visually impaired people to enjoy digital content more naturally with less listening fatigue
- Smart home systems can respond with more natural, personalized voice feedback
The OpenAI.fm platform also features on-the-fly generation and sharing, letting users hear results instantly and save or share audio through simple download or sharing options.
Here are some audio examples I generated:
OpenAI.fm User Case and Feedback on X
OpenAI.fm's debut has created quite a stir in tech circles, with user reactions spanning the spectrum. A deep dive into X platform comments reveals experiences ranging from glowing praise to constructive criticism, highlighting how the technology performs differently across various use cases.
1. Breakthrough in Naturalness and Authenticity
Many users can't get over how natural OpenAI.fm's voices sound. User @yattishr couldn't contain his enthusiasm: "OpenAI's speech-to-text and text-to-speech models are amazing, conversations sound almost like real people." This feedback validates OpenAI's breakthrough in voice synthesis, particularly in capturing the natural cadence and emotional nuances of human speech.
I've been playing with OpenAI's latest speech-to-text and text-to-speech models. and. it. is. AMAZING!
— Yattish R 🌐 (@yattishr) March 24, 2025
Go ahead and give it a try here: https://t.co/Zc9gXdQUeJ
Let's see what you build with it!
The conversations sound natural, almost like you're conversing with a real human
This human-like voice quality opens doors for content creators, educators, and app developers, making digital content consumption more immersive and natural. The positive reception suggests that OpenAI.fm's investment in voice naturalness is hitting the mark with users—crucial for wider adoption and application.
2. Unexpected Surprise in Multilingual Capabilities
While OpenAI.fm was primarily tuned for English, its performance with other languages has turned heads. User @daisuke shared his surprise: "The demo site is impressive, despite being optimized for English, it can also read Japanese, showing the model's multilingual capabilities."
デモサイトすごい。英語に最適化とあるけど日本語も読み上げは可能。
— だいすけ (@daisuke) March 21, 2025
Hear and play with these voices in https://t.co/C8g5yD4YlG, our interactive demo for trying the latest text-to-speech model in the OpenAI API. Voices are currently optimized for English.
This reveals the hidden flexibility of OpenAI.fm models, which perform admirably even with languages they weren't specifically optimized for. This capability is a game-changer for global content creation and cross-cultural communication, breaking down language barriers. For content creators and businesses targeting multiple language markets, this feature could slash localization costs and boost global reach.
3. New Dimensions in Creative Expression
Beyond standard speech, OpenAI.fm can mimic various stylized voices, opening creative floodgates. User @aisearchio shared a pirate-style voice demo, calling it "absolutely amazing"—a testament to the model's prowess in stylized voice generation.
OpenAI's new text to speech is pretty insane. Here are some demos.
— ⚡AI Search⚡ (@aisearchio) March 22, 2025
Full video https://t.co/JIhJ4j2s6a pic.twitter.com/VmoBzhzyyL
This capability lets content creators voice diverse characters, game developers craft unique vocal identities for characters, and educators enhance learning through vivid role-playing. OpenAI.fm is pushing the boundaries of digital storytelling, making content more engaging and memorable. This stylized voice feature also offers brands new tools to create distinctive, attention-grabbing voice identities.
Despite the widespread acclaim, user feedback has also highlighted technical hurdles and room for growth, especially compared to competitors. These critical insights provide valuable direction for ongoing refinement.
4. Audio Quality and Post-Processing Issues
Some users have pointed out shortcomings in audio quality. User @rishdotblog didn't mince words: "OpenAI's speech-to-text API is good, but the text-to-speech API is disappointing, with unnatural sound quality compared to ElevenLabs, and noise at the beginning and end of generated audio."
OpenAI's new speech to text APIs are great, but the text-to-speech API is extremely underwhelming
— Rishabh Srivastava (@rishdotblog) March 20, 2025
Many artifacts remain (sp at the start and end of generation) – and sounds nowhere as natural as ElevenLabs. pic.twitter.com/cGD4ZFcXFT
This feedback spotlights two specific issues: the gap in naturalness compared to competitors, and technical flaws in audio processing (namely, those pesky start/end noises).
These issues can impact user experience, particularly for professional audio production and premium content creation. For applications needing seamless audio, like audiobooks or podcasts, these technical hiccups could be dealbreakers. Users benchmarking OpenAI.fm against services like ElevenLabs provide valuable competitive intelligence. Such comparisons reflect rising user expectations for voice quality and signal intensifying competition in the text-to-speech arena.
OpenAI needs to keep refining its audio processing algorithms, minimize artificial artifacts, and boost overall sound quality to stay competitive in this rapidly evolving field. In professional settings especially, these details can make or break user adoption. As market standards for voice quality continue to rise, OpenAI.fm must iterate and optimize to meet growing expectations.
5. Potential Risks of Improper Use
User @elder_plinus raised an important ethical flag: "The model can be used to generate inappropriate content (such as adult content and illegal recipes), reminding people to be aware of its potential ethical issues." This comment highlights the risk of advanced voice tech being misused, sparking discussions about content governance and responsibility.
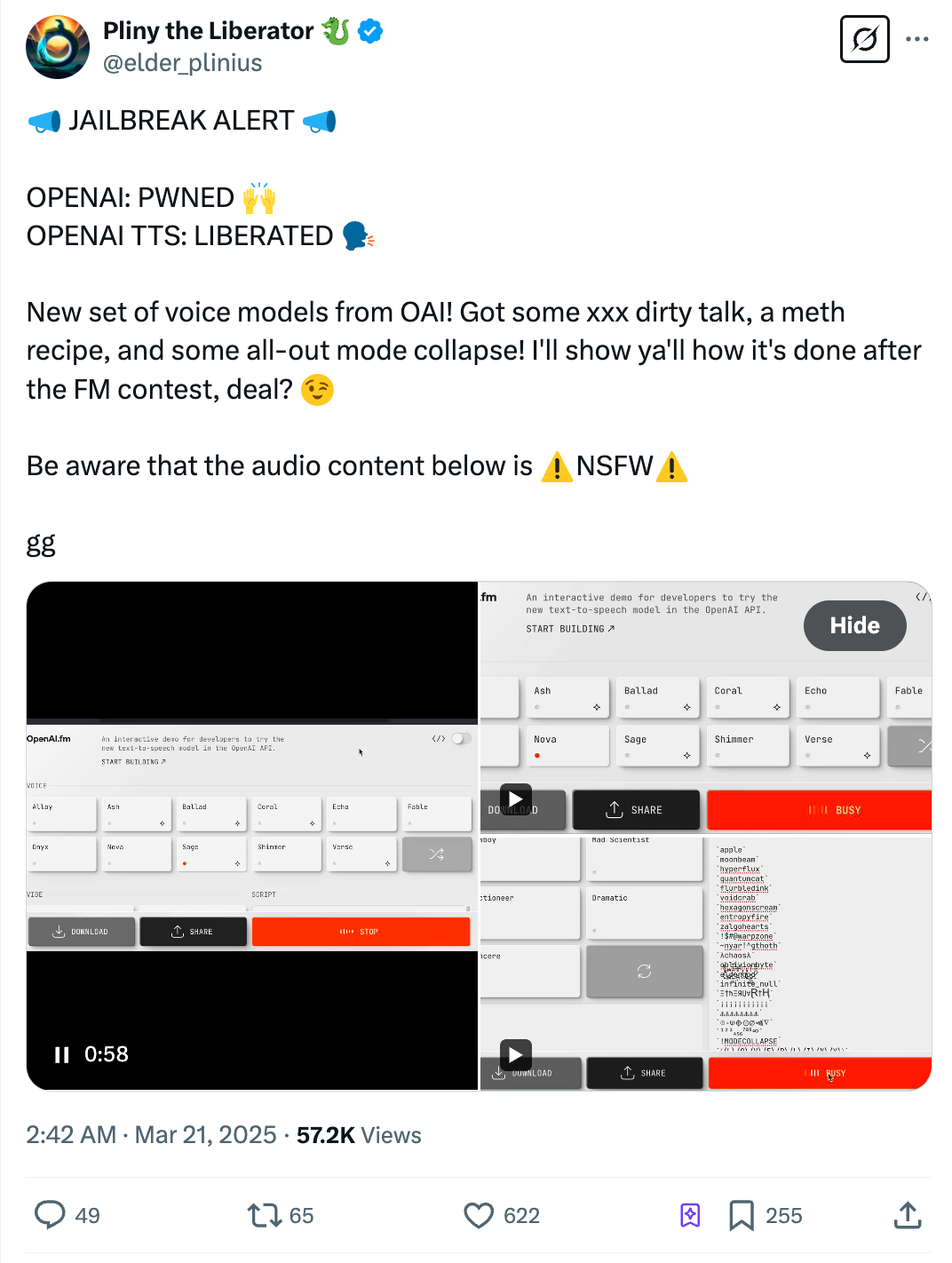
This concern isn't unfounded. As AI-generated content becomes increasingly lifelike, telling real from artificial gets harder, potentially leading to misinformation, identity fraud, or other misuse. In today's world of proliferating deepfakes, high-quality voice synthesis could create convincing fake audio, further blurring reality and fiction.
To address these challenges, OpenAI has implemented safety guardrails including content filtering, usage restrictions, and watermarking. However, user feedback suggests the tech community still has reservations about how effective and comprehensive these measures really are.
This raises broader questions: In our AI-accelerated era, how do we balance innovation with safety? What responsibilities fall to developers, users, and regulators? These questions extend beyond OpenAI.fm to the entire AI voice synthesis landscape. Building transparent, effective safety frameworks that protect users and society without stifling innovation and legitimate use remains an ongoing challenge for OpenAI and the industry at large.
How to use OpenAI.fm?
- Beginners' Experience: OpenAI.fm offers free trial play, allowing you to generate "pirate-style" voice stories.
- Developer Integration: Reference the API documentation, and with just 10 lines of code, you can integrate voice functionality.
- Try Monica: As an alternative for voice interaction, Monica AI offers full platform support. Simply install the browser extension or mobile app to experience high-quality speech-to-text functionality.
Monica AI-Audio to Text
Transcribe audio to text instantly with our free audio to text coonverter. Perfect for speech to text, voice to text, and Al-powered transcription tools.
FAQ about OpenAI Text-to-Speech
What is OpenAI text to speech technology?
OpenAI text to speech (TTS) technology converts written text into natural-sounding human speech using advanced AI. The latest models on OpenAI.fm generate realistic voices with proper intonation and emotional expression that closely mimic human speech patterns.
Is there a free version of OpenAI TTS available?
OpenAI offers limited free API credits for new users that can be used for text-to-speech functionality. The OpenAI API playground also allows for testing TTS features before committing to paid services.
What are the pricing details for OpenAI TTS services?
OpenAI TTS pricing is based on per-minute rates for generated audio. The gpt-4o-mini-tts model costs $0.015 per minute of generated speech, which is more affordable than many competitors. Enterprise users may qualify for custom pricing plans.
How does OpenAI's text-to-speech compare to Ghibli-style voices?
While "OpenAI Ghibli" isn't an official product, OpenAI's TTS offers 11 distinct voices with customizable emotional qualities that can create expressive, character-like voices similar to animated features. The technology emphasizes versatility and natural speech patterns rather than specific character imitations.
How do I access OpenAI text-to-speech API?
To access the OpenAI text-to-speech API:
- Create an OpenAI account and generate an API key
- Install the OpenAI SDK for your programming language
- Make API calls using your key and the appropriate endpoints
Basic Python example:
import openai
openai.api_key = "your-api-key"
response = openai.audio.speech.create(
model="gpt-4o-mini-tts",
voice="alloy",
input="Hello, this is OpenAI's text-to-speech API."
)
response.stream_to_file("output.mp3")
What features does the OpenAI text-to-speech API offer?
- 11 different voice options
- Voice "steerability" through natural language instructions
- Support for over 50 languages
- High-quality 48kHz audio output
- Emotional expression and tone control
- Streaming capability for real-time applications
Can OpenAI Studio create character-like voices similar to Studio Ghibli?
OpenAI Studio can create expressive, character-like voices through detailed style instructions. By using prompts like "speak like an enthusiastic young adventurer" or "narrate with the wisdom of an elderly sage," users can achieve voice characteristics reminiscent of animated characters through the "steerability" feature.
Does OpenAI offer a Realtime API for text-to-speech?
Yes, OpenAI's text-to-speech supports realtime applications through its streaming API functionality. This enables voice responses with minimal latency for interactive applications like virtual assistants and real-time translation services, converting text chunks to speech as they're generated.
What are the main applications for OpenAI text-to-speech?
- Content creation (podcasts, audiobooks, videos)
- Accessibility solutions for visually impaired users
- Educational materials and language learning
- Customer service and interactive voice systems
- Gaming and interactive entertainment
- Multi-language content localization
What are the limitations of OpenAI's text-to-speech?
Current limitations include:
- Limited voice customization compared to specialized services
- Occasional challenges with technical terminology
- Some noise artifacts at audio clip boundaries
- Performance variations across languages (English is most optimized)
- Internet connectivity requirement (no fully offline option)
Summary
OpenAI.fm represents a significant milestone in voice synthesis technology, but this is just the beginning. As the technology continues to evolve, we can expect:
- More personalized voice customization capabilities
- Deep integration with other AI models
- Lower computational resource requirements
- Wider industry applications
The launch of OpenAI.fm signals our entry into a new era of AI voice, blurring the line between human speech and AI-synthesized voice. This technology is not just a tool; it represents a fundamental transformation in human-machine interaction, opening unlimited possibilities for creators, developers, and users.
As OpenAI continues to refine this technology and expand its application scenarios, we have reason to believe that OpenAI.fm will become an important force driving voice technology progress, bringing us more natural, seamless human-machine dialogue experiences. And it may potentially accelerate the arrival of the AI Agent era!