
GPT-4.1
OpenAI 最新智能模型 GPT-4.1:具有卓越的编程能力、百万符号处理能力和精确的指令执行。
GPT-4.1:重新定义先进的 AI 能力
编码能力突破,效率提升
GPT 4.1 在 SWE-bench 测试中达到 54.6% 的完成率,远超 GPT-4o 的 33.2%。它在探索代码库和生成可运行的、通过测试的代码方面表现出色。
实际改进包括 3 倍更好的代码差异可靠性和增强的前端开发(80% 评审者偏好)。冗余编辑从 9% 降至 2%。
在功能开发、调试或代码审查中,GPT-4.1 提供精确、高效的支持,成为开发者的必备工具。
实际改进包括 3 倍更好的代码差异可靠性和增强的前端开发(80% 评审者偏好)。冗余编辑从 9% 降至 2%。
在功能开发、调试或代码审查中,GPT-4.1 提供精确、高效的支持,成为开发者的必备工具。
增强的指令遵从,更自然的对话
GPT 4.1 精通指令理解和执行,准确处理格式要求、否定指令和内容标准,精确度显著提高。
在多轮对话中,比 GPT-4o 提高了 10.5%,更好地利用对话历史,实现更连贯的沟通。
在税务分析中,GPT-4.1 展现出 53% 的准确性提升,突显其在专业法规和复杂指令上的优势。这些进步提高了AI在企业支持、专业分析和日常互动中的可靠性。
在多轮对话中,比 GPT-4o 提高了 10.5%,更好地利用对话历史,实现更连贯的沟通。
在税务分析中,GPT-4.1 展现出 53% 的准确性提升,突显其在专业法规和复杂指令上的优势。这些进步提高了AI在企业支持、专业分析和日常互动中的可靠性。
超长上下文理解能力
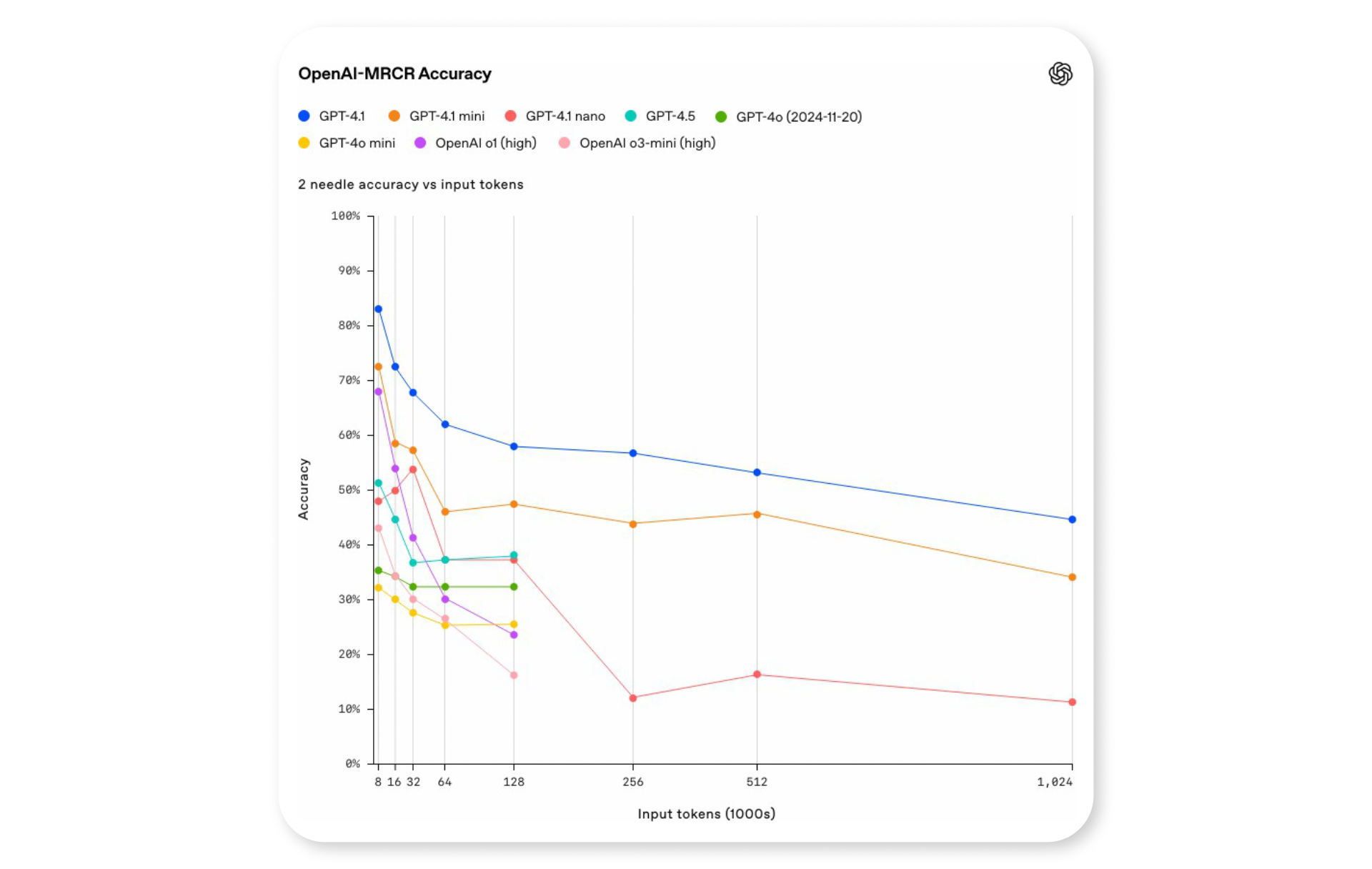
GPT 4.1 支持 100 万标记(约 750,000 字),超过《战争与和平》全文。这使得能够在保持连贯性的同时处理大量文档和代码库。
这一能力使 GPT-4.1 成为研究和法律分析的理想选择,使开发者能够创建具有更强记忆能力的更智能应用程序。
这一能力使 GPT-4.1 成为研究和法律分析的理想选择,使开发者能够创建具有更强记忆能力的更智能应用程序。
卓越的图像理解,轻松处理视频内容
GPT 4.1 的视觉能力能准确解释图像、图表和视频内容。擅长科学图表解释和视觉数学问题。
特别出色的是,它能在没有字幕的情况下理解30-60分钟的视频,并准确回答内容问题。这创造了一个全能的多媒体助手,简化了视觉内容处理。
👉 现在下载插件,体验全面的视频和图像理解能力。
特别出色的是,它能在没有字幕的情况下理解30-60分钟的视频,并准确回答内容问题。这创造了一个全能的多媒体助手,简化了视觉内容处理。
👉 现在下载插件,体验全面的视频和图像理解能力。

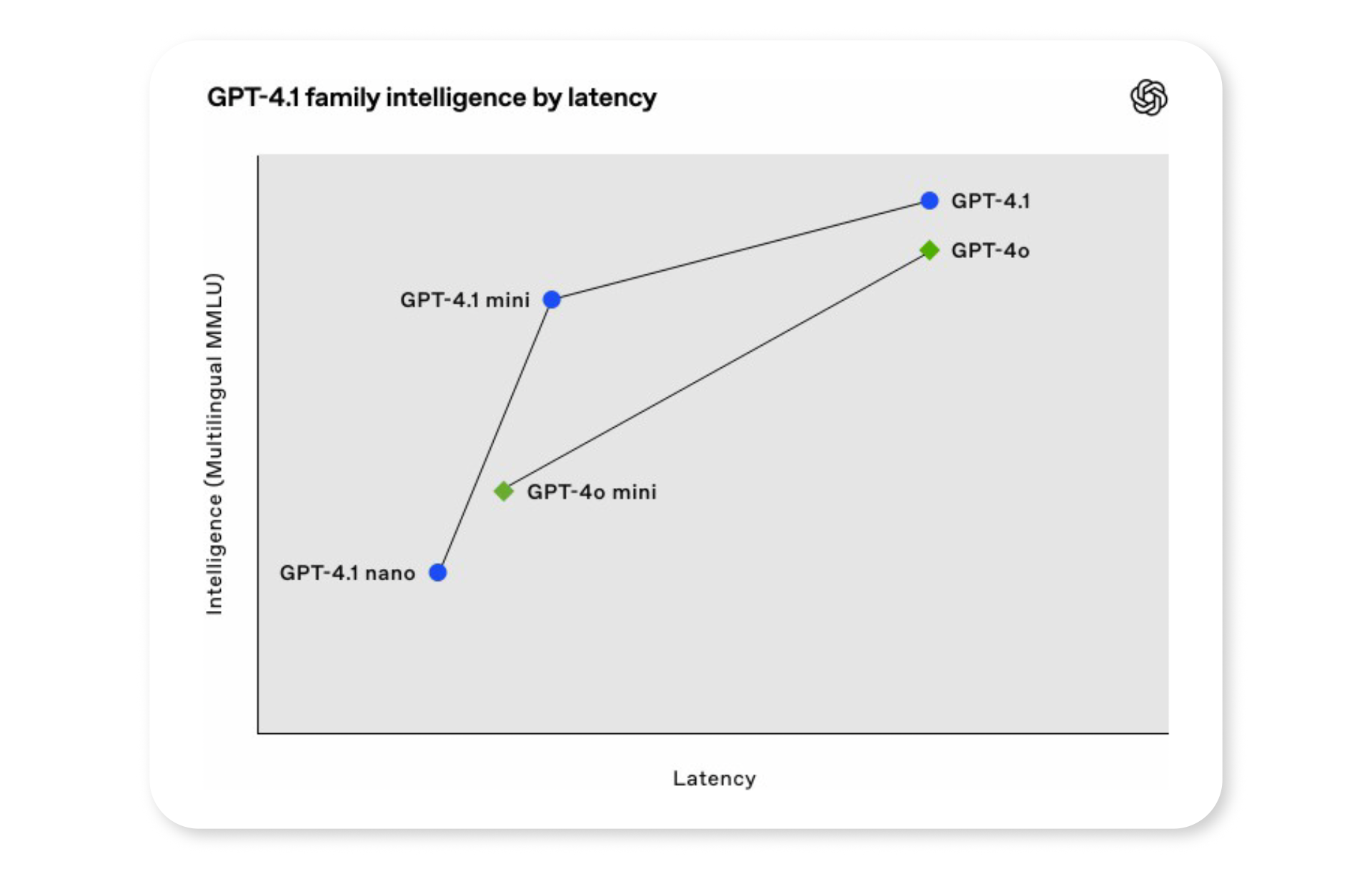
了解 GPT-4.1 模型系列
OpenAI 的 GPT 4.1 系列模型,包括 GPT 4.1 Mini 和 GPT 4.1 Nano,提供适合快速响应和低成本操作应用程序的高效经济解决方案。
比较 GPT-4.1 与其他模型
深入分析 GPT-4.1、GPT-4.5 和 Claude 3.7 Sonnet 之间的特性和性能差异,揭示它们在代码建议和其他应用领域的表现。
GPT-4.1 VS GPT-4.5
GPT-4.1 VS Claude 3.7 Sonnet
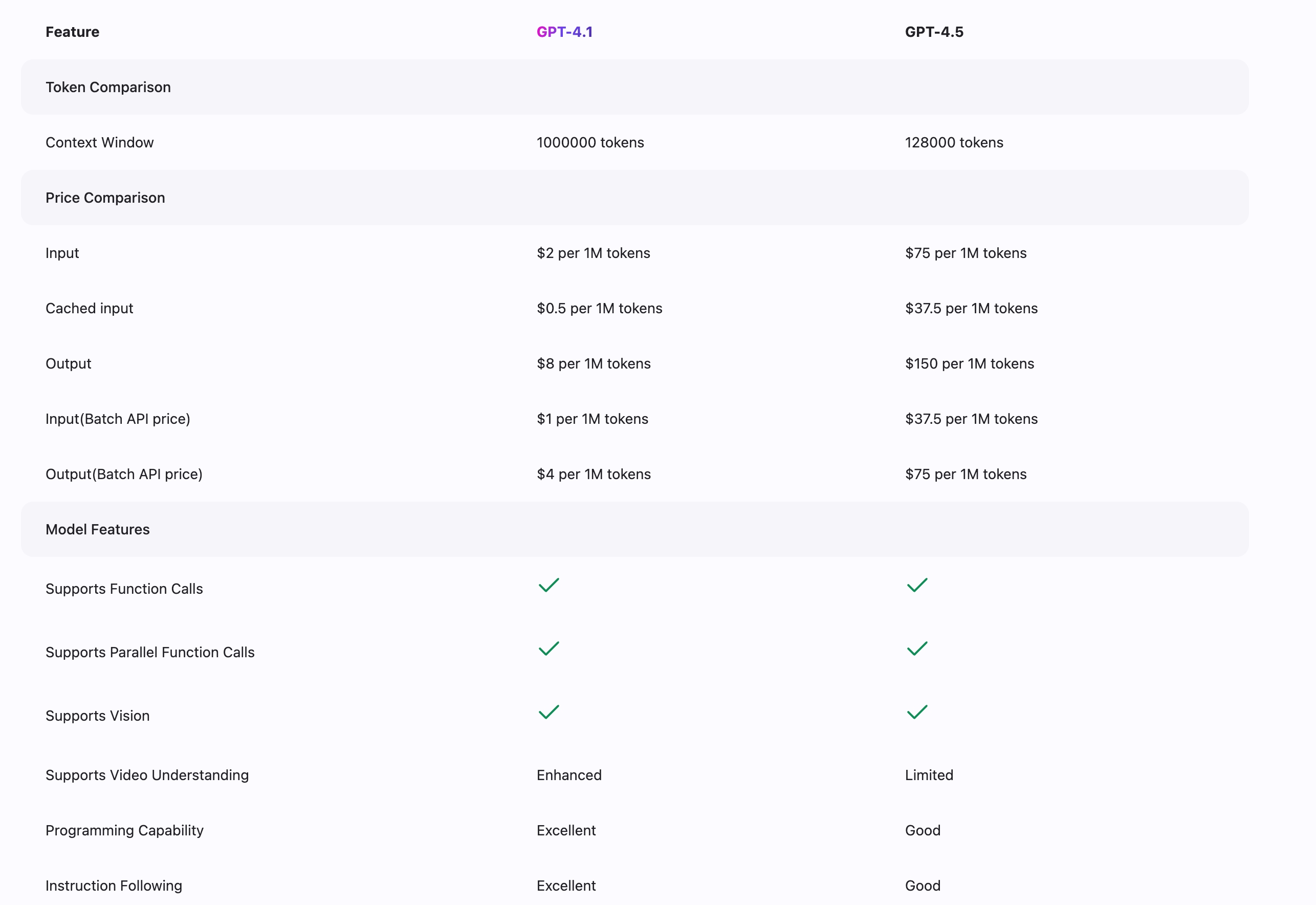
探索 GPT-4.1 和 GPT-4.5 模型之间的关键特性、能力和差异。
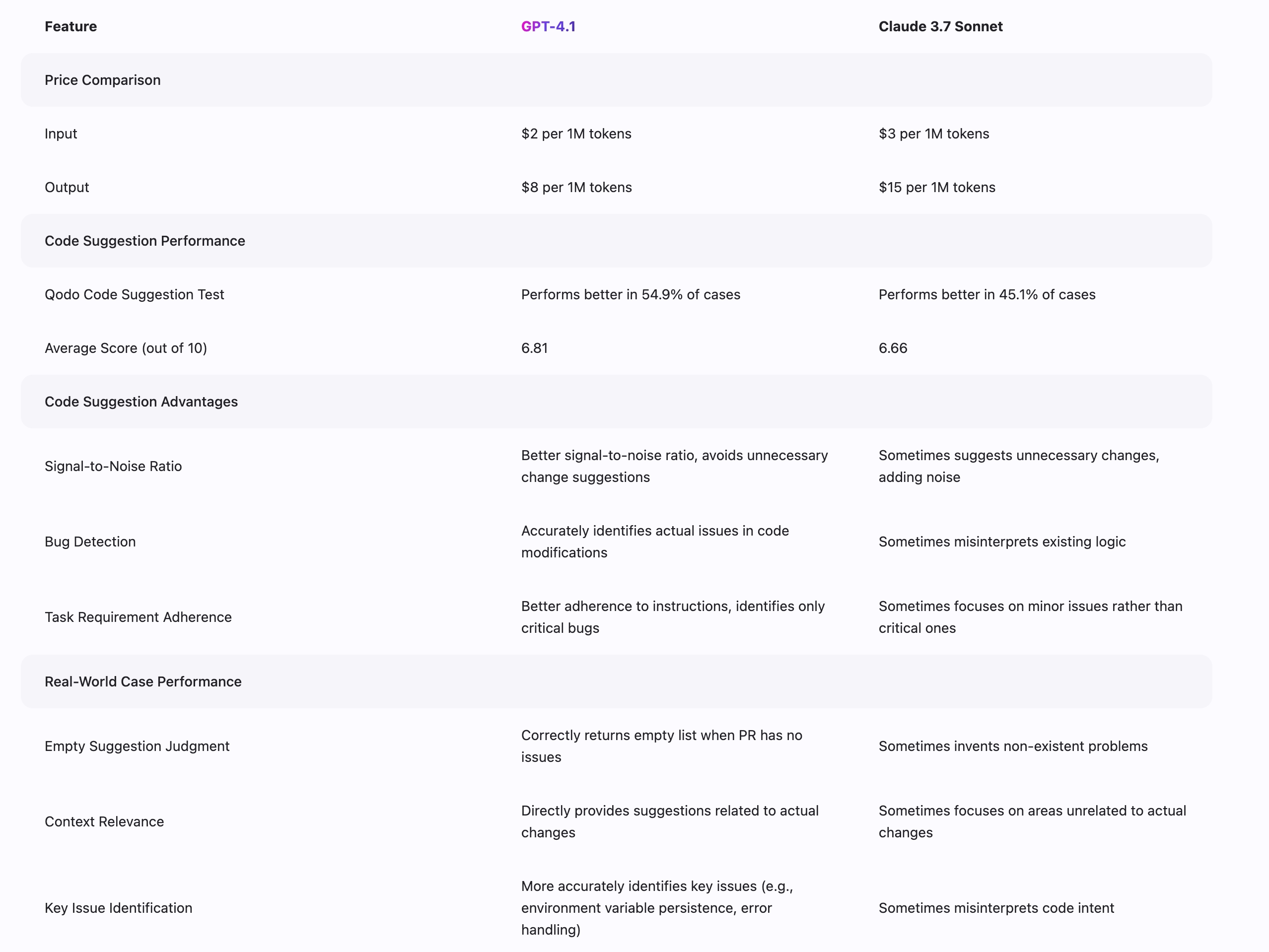
根据 Qodo.ai 的基准数据比较两个模型在代码建议中的性能
常见问题解答
GPT 4.1 是何时发布的?
GPT-4.1 于 2025 年 4 月发布,在编码、指令遵循和视觉理解能力上有显著提升。
GPT-4.1 的基准测试结果如何?
GPT 4.1 的基准测试显示在多个指标上取得了显著的提升,包括在 SWE-bench 测试中取得 54.6% 的完成率(相比之下 GPT-4o 为 33.2%),在对话连贯性上提高了 10.5%,以及在复杂税务分析上提高了 53% 的准确性。
如何访问 GPT-4.1 的 API?
可以通过 OpenAI 的开发者平台 获得 GPT 4.1 API。您需要注册 API 访问权限,并使用提供的文档和 SDK 进行集成。
GPT-4.1 是否可在 Azure 上使用?
是的,GPT 4.1 Azure 完全整合到 Azure OpenAI 服务中。
GPT 4.1 的成本结构是什么?
GPT-4.1 系列提供基于输入和输出标记的分级定价结构:GPT-4.1 标准版的输入费用为每百万标记 $2.00(缓存输入为每百万标记 $0.50),输出费用为每百万标记 $8.00。GPT-4.1 Mini 更具经济性,输入费用为每百万标记 $0.40,输出费用为每百万标记 $1.60。最具成本效益的选择是 GPT-4.1 Nano,输入费用仅为每百万标记 $0.10,输出费用为每百万标记 $0.40。
是否有 GPT 4.1 mini 版本可用?
是的,GPT-4.1 mini 提供该模型的更小版本,参数减少,为不太苛刻的应用提供性能和成本之间的平衡。它在日常任务中表现出色,同时比完整版本更经济。您可以立即在 Monica AI 上试用 GPT-4.1 mini,亲身体验其功能,看看它如何提高您的生产力,同时保持预算效率。
GPT 4.1 mini 的定价与完整版相比如何?
GPT-4.1 mini 的价格比完整版低 80%,输入成本为每百万标记 $0.40(对比 $2.00),输出成本为每百万标记 $1.60(对比 $8.00)。这使其成为小型企业和预算受限项目的理想选择,同时保持优异的性能。
GPT 4.1 与 4.5 的比较如何?
GPT-4.1 提供了 100 万标记的上下文窗口(相比之下,GPT-4.5 为 128,000 标记),在 SWE-bench 测试中达到了 54.6% 的完成率。GPT-4.1 在视觉理解和多轮对话任务中表现优异,在编程和遵循指令方面有显著优势。除此之外,GPT-4.1 比 GPT-4.5 更具成本效益,使先进的 AI 能力可供更广泛的受众使用。虽然 GPT-4.5 在某些特定推理任务中可能有优势,但 GPT-4.1 为大多数应用提供了一个出色的能力、性能和价值平衡。
GPT 4.1 与 Claude 3.7 的区别是什么?
GPT-4.1 和 Claude 3.7 代表了不同的高级 AI 方法。GPT-4.1 在代码生成(SWE-bench 中的完成率 54.6%,而 Claude 3.7 为 48.3%)和视觉理解任务中表现出色,处理复杂图像和视频内容的性能更优。它还提供了 100 万标记的更长上下文窗口。Claude 3.7 在细致推理、事实准确性和某些专业知识领域展现出优势。GPT-4.1 通常在编程任务、多模态应用和技术内容生成中更高效,而 Claude 3.7 可能在需要谨慎推理和精确指令遵循的任务中表现更好。定价也不同,GPT-4.1 通常为等效的能力提供更具竞争力的价格。
GPT-4.1 在 Reddit 上的评价如何?
GPT 4.1 的 Reddit 社区反馈非常积极,用户特别欣赏其强大的编程能力和长上下文处理。GPT-4.1 在 Reddit 讨论中的热门话题包括与 Claude 3.7 的比较、性价比和 Mini 版本的实用性。总体而言,GPT-4.1 因其代码生成质量和处理大型项目的能力而受到技术社区的高度赞誉。