スマートフィル
スマートフィルは Monica の強力なウェブツールで、プロフェッショナルなデータアシスタントとして機能し、さまざまな表タスクを自動化して手作業の時間を大幅に節約します。特に、製品マネージャー、研究者、営業担当者、アナリスト、投資家など、頻繁に表データを検索および処理する必要がある人に役立ちます。
コアの利点
- 自動化:ワンクリックで複雑な表タスクを完了
- 多用途: 競合調査、文献レビュー、営業リード管理などに対応
- AI駆動: 高度なAI技術を利用したインテリジェントなデータ処理
- 効率と正確性: 作業効率を大幅に向上させ、人為的なエラーを減少
使用例
- 競合調査: 競合情報を自動収集し、迅速に分析表を生成
- 文献レビュー:文献から重要な情報をインテリジェントに抽出し、レビュー表の作成を容易にする
- 営業リード管理:潜在顧客情報を自動的に補完し、営業効率を向上させる
- ユーザーフィードバック分析:ユーザーフィードバックをインテリジェントに分類し、迅速に分析レポートを生成する
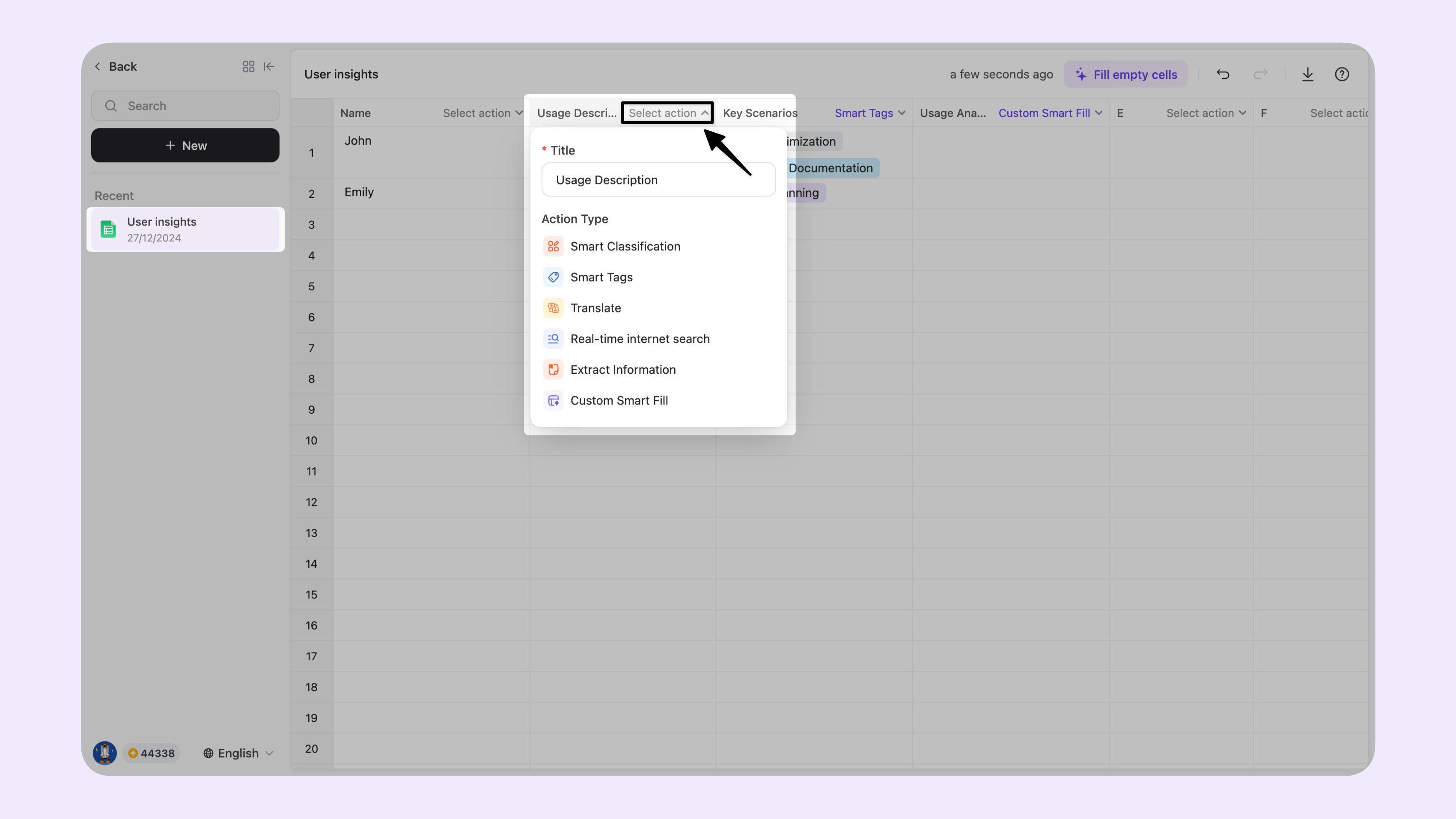
指示の種類
クイックナビゲーション
- スマート分類:表のテキスト内容を自動的に分類し、プリセットカテゴリとインテリジェント分類モードの両方をサポートします。
- スマートタグ:コンテンツに多次元タグを追加し、情報のさまざまな側面を包括的に記述および分析します。
- リアルタイムインターネット検索:インターネット情報を自動的に取得し、要件を満たすデータをインテリジェントに抽出します。
- 情報抽出:非構造化テキストから特定の情報を識別して抽出し、構造化された表データに変換します。
- カスタムスマートフィル:自然言語指示を通じてテキスト処理ルールを定義し、高品質なコンテンツを一括生成します。
スマート分類
スマート分類を使用すると、表のテキストコンテンツを自動的に分類できます。この強力なテキスト分類指示はコンテンツを理解し、各エントリを最も適切なカテゴリに正確に割り当てます。ターゲット列を選択し、分類ルールを設定するだけで、システムが自動的に分類プロセスを完了します。各エントリは唯一の最適なカテゴリに分類され、結果は指定された結果列に自動的に入力されます。
スマート分類は2つの動作モードをサポートしています:
- プリセットカテゴリモード:固定されたカテゴリオプションを事前に定義でき、システムはコンテンツをこれらのカテゴリにインテリジェントにマッチングします
- インテリジェント分類モード: 自然言語で分類ルールを記述することで、システムがルールに基づいてカテゴリをインテリジェントに判断します
例えば:
列A (ユーザーフィードバック) 列B (フィードバックタイプ分類)
インターフェースが頻繁に遅れる、ユーザー体験に影響 -> バグ報告
ダークテーマ機能の追加を提案 -> 機能リクエスト
ソフトウェアは素晴らしく、インターフェースはクリーン -> ポジティブレビュー
データをエクスポートできない、緊急! -> バグ報告
スマートタグ
スマートタグは多次元のコンテンツ注釈方法を提供します。スマート分類とは異なり、スマートタグは単一のコンテンツに複数のタグを追加することができ、情報のさまざまな側面をより包括的に記述および分析することができます。この機能は、複数の次元から情報を理解し分類する必要がある場合に特に役立ちます。
スマートタグの主な特徴:
- プリセットタグモードをサポート:事前定義された�タグライブラリから最も関連性の高いタグの組み合わせを選択
- インテリジェントタグモードをサポート:コンテンツに基づいて関連タグを自動生成し、プリセットタグライブラリを必要としない
例えば:
列A(製品レビュー) 列B(スマートタグ結果)
美しいインターフェースデザイン、スムーズな操作 -> [美しいUI、スムーズなパフォーマンス]
手頃な価格、迅速なカスタマーサービス -> [コストパフォーマンスが良い, 優れたサービス]
強力な機能だが学習コストが高い -> [機能が豊富, 使いやすさが低い]
リアルタイムインターネット検索
リアルタイムインターネット検索は、表データの補完に強力な自動化機能を提供します。インターネットから関連情報をリアルタイムで取得し、検索意図を賢く理解し、要件を満たすデータを抽出します。こ�の指示の主な利点は、情報の検索と抽出プロセスを自動化し、手動でウィンドウを切り替えたりコピー&ペーストする必要がないことです。
リアルタイムインターネット検索のワークフロー:
- 検索キーワードのソース列を指定
- 特定の検索要件とフィルタリング条件を設定
- 情報抽出ルールとフォーマット要件を設定
- システムが自動的に検索を実行し、関連情報を抽出します
- 検索結果が自動的にターゲット列に入力されます
例えば:
列A(会社名) 列B(検索要件:基本的な会社情報を取得)
テスラ -> 2003年に設立され、米国テキサス州オースティンに本社を置く。電気自動車とクリーンエネルギーの世界的リーダー。
アマゾン -> 1994年に設立され、米国シアトルに本社を置く。世界最大の電子商取引およびクラウドコンピューティングプラットフォームの一つ。
情報を抽出
情報抽出指示は、非構造�化テキストから特定の情報を識別して抽出するために特別に設計されています。テキスト内容を理解し、必要な情報を正確に特定して抽出し、それを構造化された表データに変換することができます。このプロセスは単純なキーワード抽出を超え、文脈理解と意味解析を組み込んで、抽出結果の正確性と完全性を確保します。
情報抽出の主な機能:
- テキスト内の重要な情報を知的に識別
- 構造化された出力形式の提供
- カスタム抽出ルールのサポート
例えば:
列A(文献要約) 列B(研究方法の抽出) 列C(研究結論の抽出)
本研究ではアンケート調査法を用い、500人のユーザーを調査しました。研究によると、90%のユーザーが製品に満足していると表明しました。
-> 列B:アンケート調査法、サンプルサイズ500
-> 列C:90%のユーザー満足度
カスタムスマートフィル
カスタムスマートフィルの指示はGPT-4o miniモデルによって駆動されます。自然言語の指示を通じて、テキスト処理ルールを定義することができ、AIはあなたの意図を理解し、対応する処理を実行します。この指示は、高品質なテキストコンテンツを一括生成するのに優れており、例えば、一つのコピーを異なるソーシャルメディアプラットフォームに適したバージョンに迅速に書き換えたり、製品説明をより魅力的なマーケティングコピーに変換したりすることができます。
カスタムスマートフィルがサポートする処理タイプ:
- マルチプラットフォームコピーの書き換え
- マーケティングコピーの最適化
- テキストスタイルの変換
- コンテンツの拡張または要約
- 多言語ローカライズ
- 専門用語の変換
- テキストトーンの調整
例えば:
シナリオ1:マルチプラットフォームのコピーリライト
列A(元のコピー) 列B(処理要件:Instagramスタイルにリライト)
新しいスマートフィル機能が登場、一クリックで表データを処理 -> ✨ Introducing Smart Fill: Transform your spreadsheet work with one-click automation. Say goodbye to manual data processing! #ProductivityTools #WorkSmarter #OfficeHacks
シナリオ2:製品機能からマーケティングコピーへ
列A(機能説明) 列B(処理要件:ユーザー価値を強調するマーケティングコピーに変換)
スマート分類機能はテキスト内容を自動で分類できます -> AIをあなたの分類アシスタントにして、面倒な手動分類にさようなら!スマート分類はあなたの内容を瞬時に理解し、すべての情報を正確に分類し、大量の時間を節約します
シナリオ3:異なるシナリオにおけるトーンの調整
列A(元の内容) 列B(処理要件:正式なビジネスメールのトーンに調整)
ご要望を受け取り、対応中です。すぐにご連絡いたします -> ご要望をありがとうございます。情報を受け取り、現在積極的に処理中です。できるだけ早く解決策を提供いたします。
始めに
- スマートフィルのウェブページにアクセス
- テーブルテンプレートを選択するか、ゼロから始める
- テーブルヘッダーを設定し、必要なスマート処理指示を選択する
- 元のデータを入力し、「空のセルを埋める」ボタンをクリックする
- AIが自動処理を完了するのを待ち、結果をダウンロードする
使用のヒント
- 適切なテーブルヘッダーを設定することで、AIの認識と処理の精度を向上させることができます
- バッチ処理の前に単一セルでテストし、結果が期待に沿うことを確認する
- テンプレート機能を活用して、よく使う表の構造を保存し再利用する
🚀 今す�ぐサブスクリプションをアップグレードして、すべてのプレミアム機能をアンロック
- あなたの考えや提案を共有して、より良い Monica を一緒に作りましょう
- Monica のソーシャルメディアをフォローして、最新のAI情報を即座に入手:🐦 X (Twitter), 💼 LinkedIn, 📸 Instagram